The FileReader API in HTML5 allows web browsers to access user files without uploading the files to the web servers. It not only lightens the load of web server but also saves the time of uploading files. It is very easy to use FileReader.readAsText() to process a 300K log file. However, when the file size grows to 1GB, or even 2GB, then the page might crash in browser or not function correctly. This is because readAsText() loads the full file into memory before processing it. As a result, the process memory exceeds the limitation. To prevent this issue, we should use FileReader.readAsArrayBuffer() to stream the file when the web application needs to process huge files, so you only hold a part of the file in the memory.
Test Scenario
Our test scenario is to get the log time range using JavaScript from a given IIS log on local disk.
Sample IIS log:
#Software: Microsoft Internet Information Services 10.0
#Version: 1.0
#Date: 2016-08-18 06:53:55
#Fields: date time s-ip cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Referer) sc-status sc-substatus sc-win32-status time-taken
2016-08-18 06:53:55 ::1 GET / - 80 - ::1 Mozilla/5.0+(Windows+NT+10.0;+WOW64;+Trident/7.0;+rv:11.0)+like+Gecko - 200 0 0 476
2016-08-18 06:53:55 ::1 GET /iisstart.png - 80 - ::1 Mozilla/5.0+(Windows+NT+10.0;+WOW64;+Trident/7.0;+rv:11.0)+like+Gecko http://localhost/ 200 0 0 3
2016-08-18 08:45:34 10.172.19.198 GET /test/pac/wpad.dat - 80 - 10.157.21.235 Mozilla/5.0+(Windows+NT+6.1;+Win64;+x64;+Trident/7.0;+rv:11.0)+like+Gecko - 404 3 50 265
2016-08-18 08:46:44 10.172.19.198 GET /test/pac/wpad.dat - 80 - 10.157.21.235 Mozilla/5.0+(Windows+NT+6.1;+Win64;+x64;+Trident/7.0;+rv:11.0)+like+Gecko - 200 0 0 6
Our target is to get the time range of this IIS log
- Start time: 2016-08-18 06:53:55
- End time: 2016-08-18 08:46:44
Implementation using readAsText()
It is quite easy and clear to implement the functionality using readAsText(). After getting the whole content of the file in a string, iterates each line from the beginning and get the string of first 19 characters, then check if it matches the date and time format. If it does, the string is the start time. In the same way, get the end time by iterating each line from the end.
<input type="file" id="file" />
<button id="get-time">Get Time</button>
<script>
document.getElementById('get-time').onclick = function () {
let file = document.getElementById('file').files[0];
let fr = new FileReader();
fr.onload = function (e) {
let startTime = getTime(e.target.result, false);
let endTime = getTime(e.target.result, true);
alert(`Log time range: ${startTime} ~ ${endTime}`);
};
fr.readAsText(file);
};
function getTime(text, reverse) {
let timeReg = /\d{4}\-\d{2}\-\d{2} \d{2}:\d{2}:\d{2}/;
for (
let i = reverse ? text.length - 1 : 0;
reverse ? i > -1 : i < text.length;
reverse ? i-- : i++
) {
if (text[i].charCodeAt() === 10) {
let snippet = text.substr(i + 1, 19);
if (timeReg.exec(snippet)) {
return snippet;
}
}
}
}
</script>
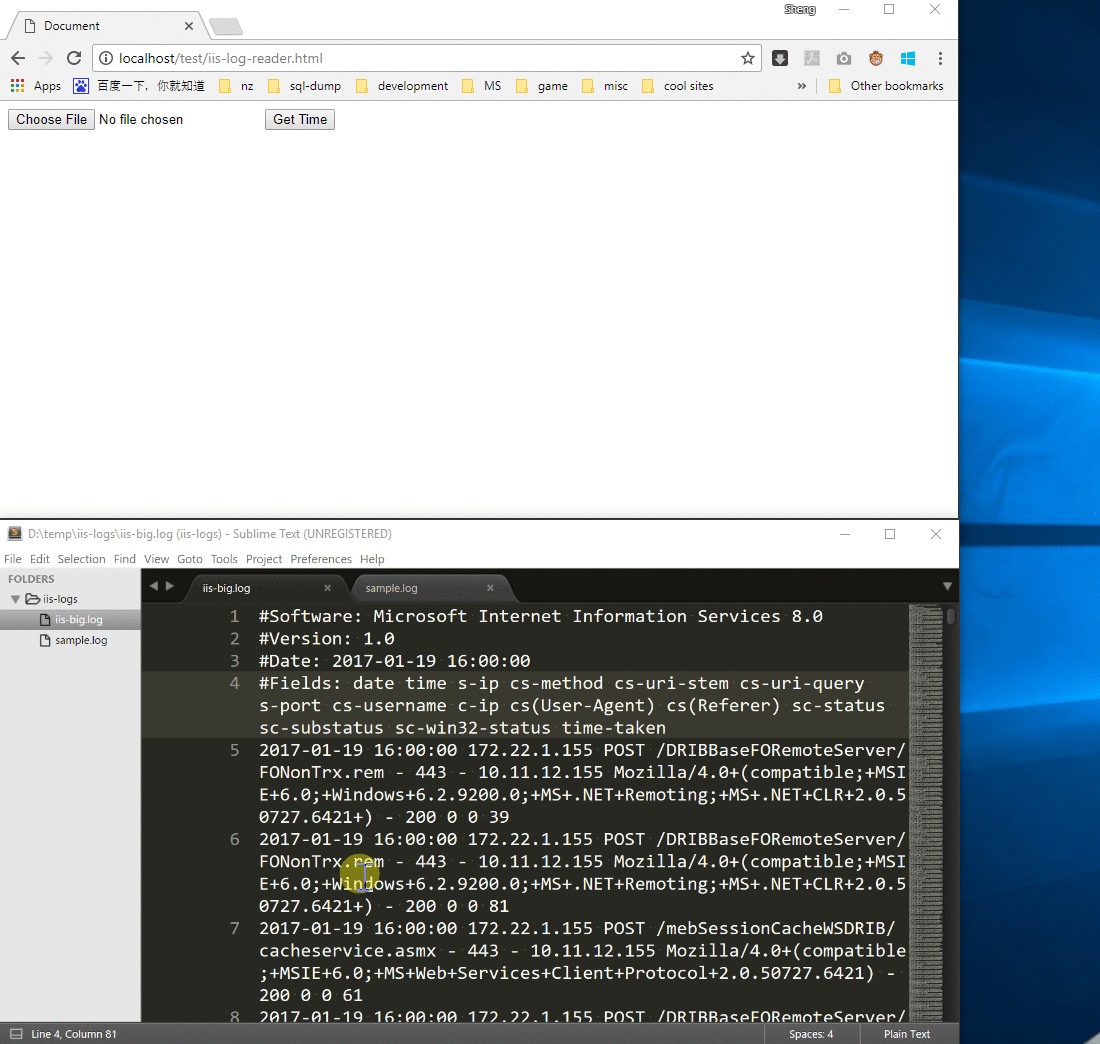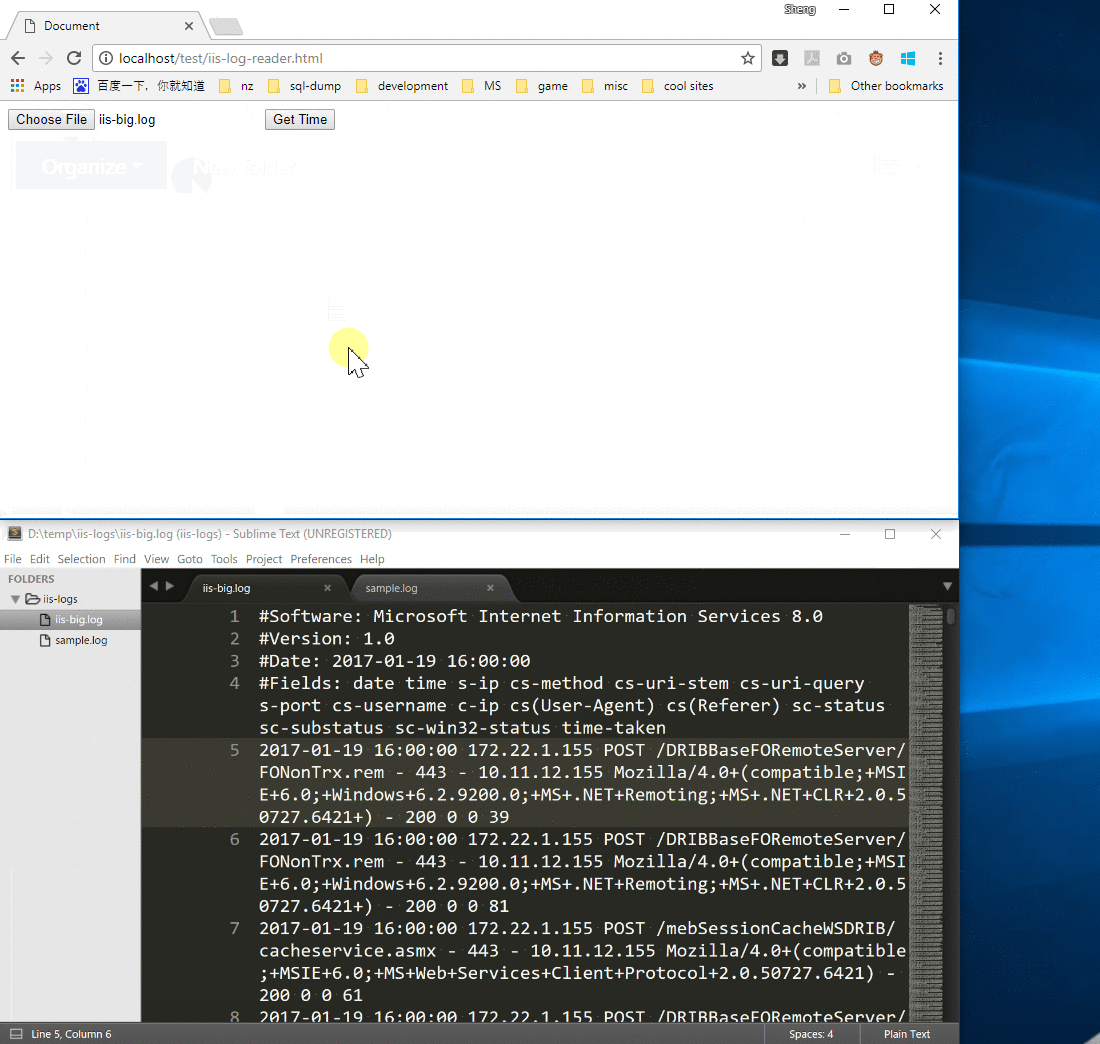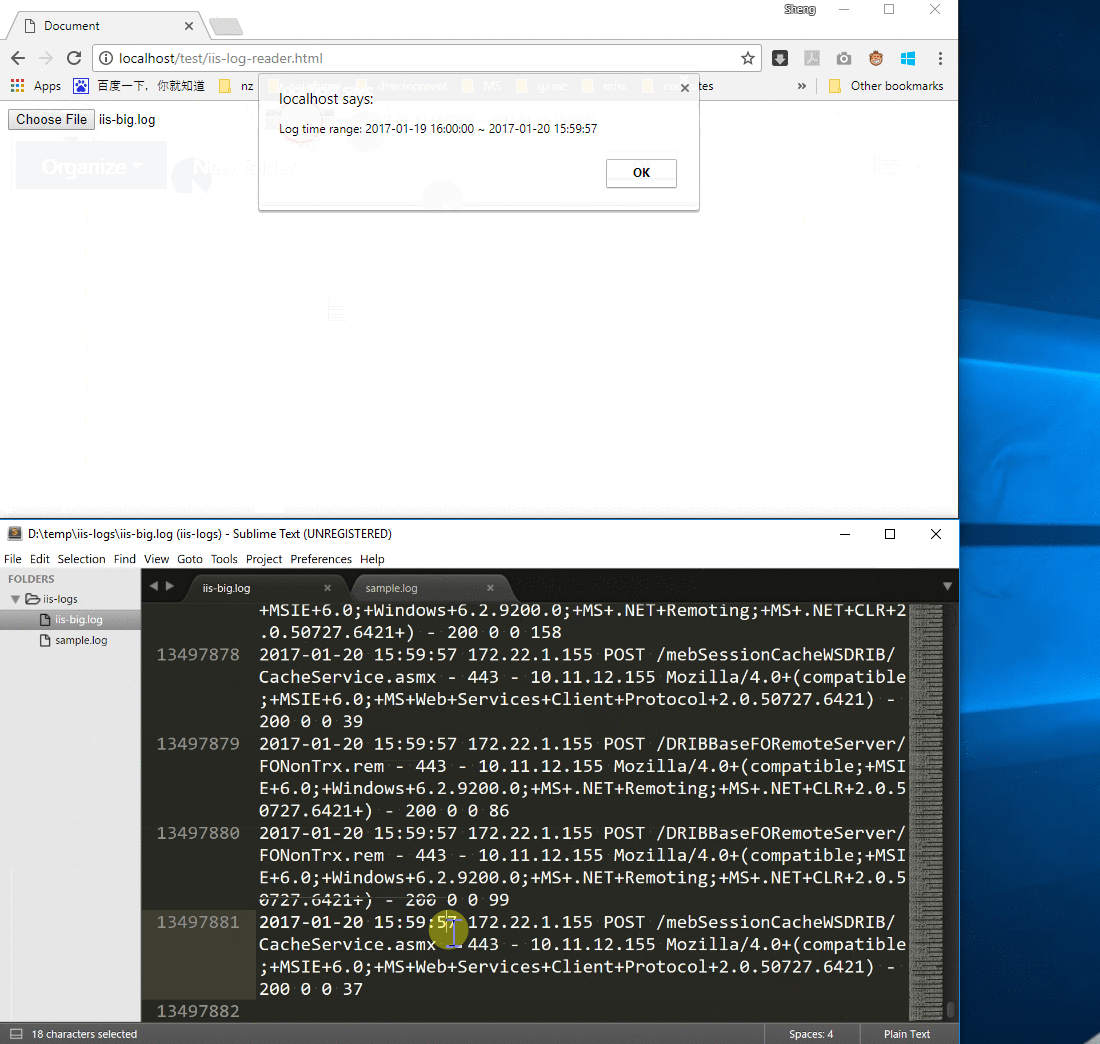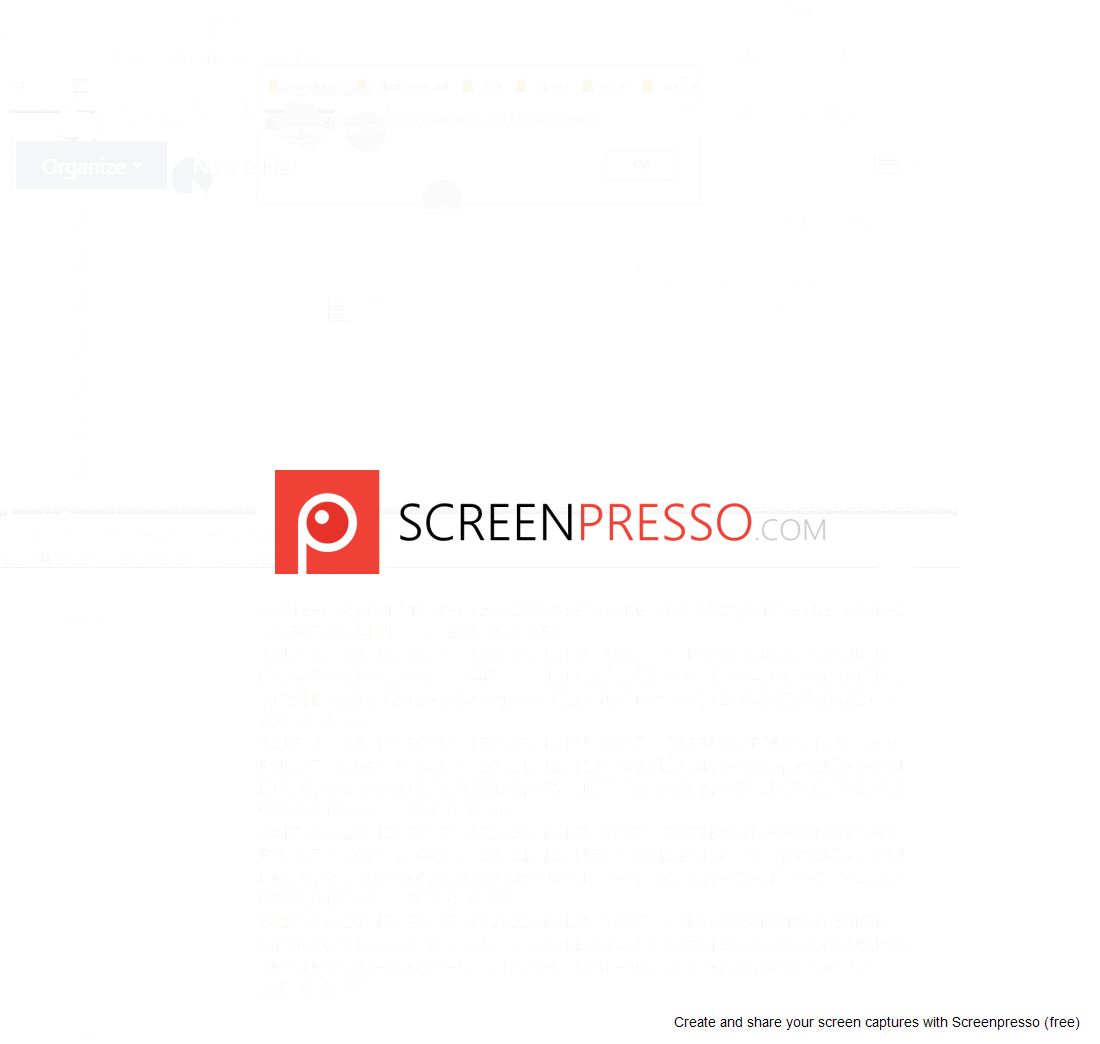
The result of processing the sample IIS log (file size: 1K) matches our expectation.
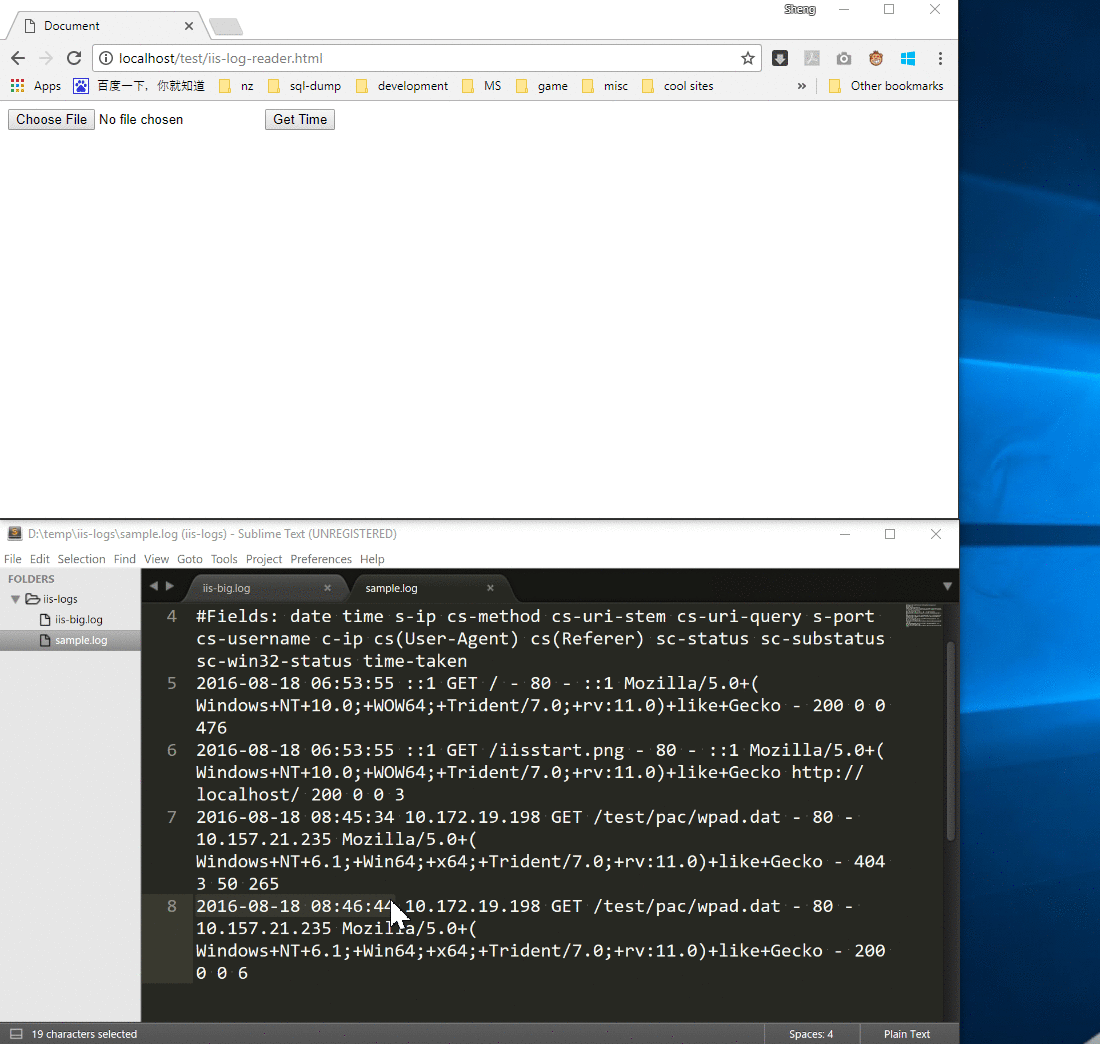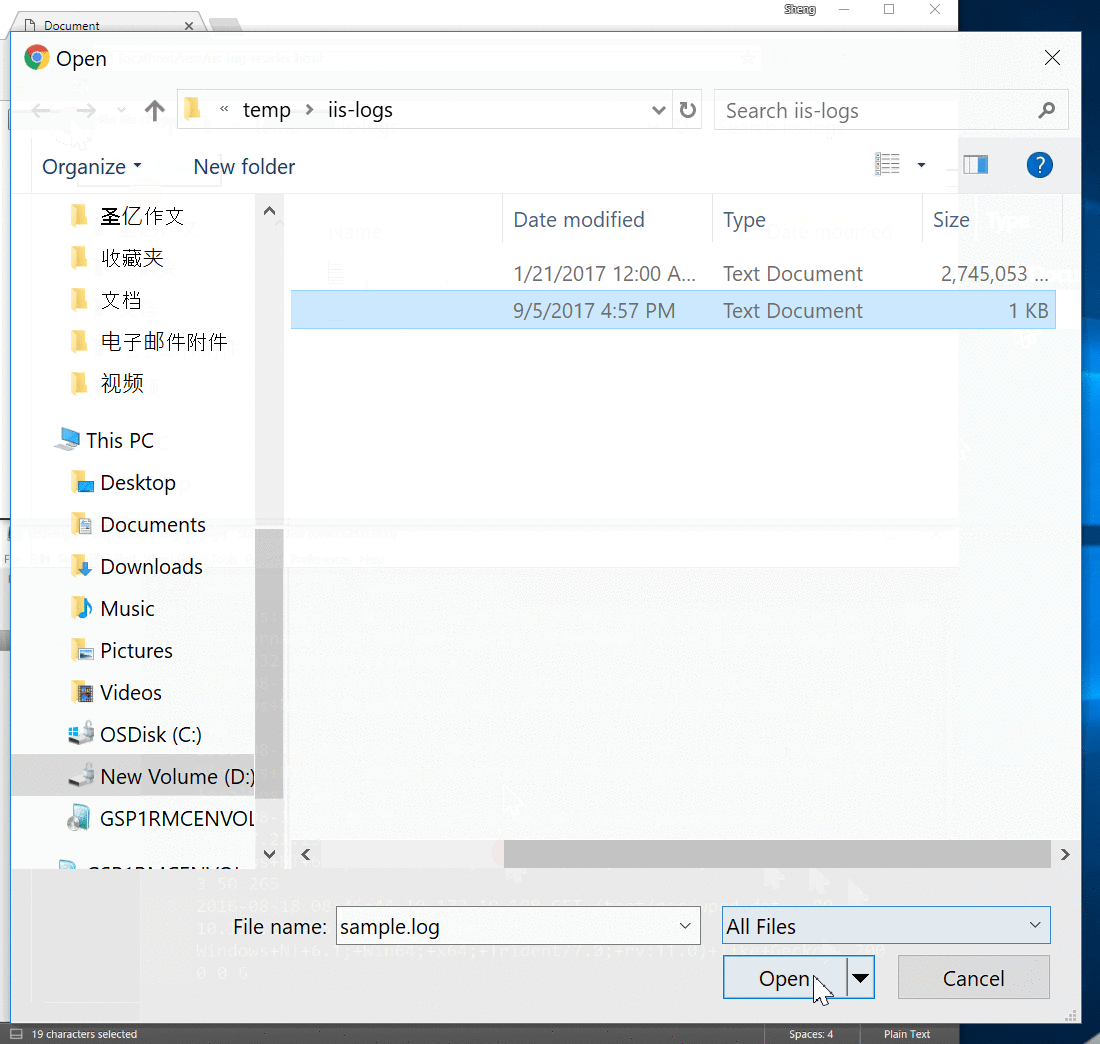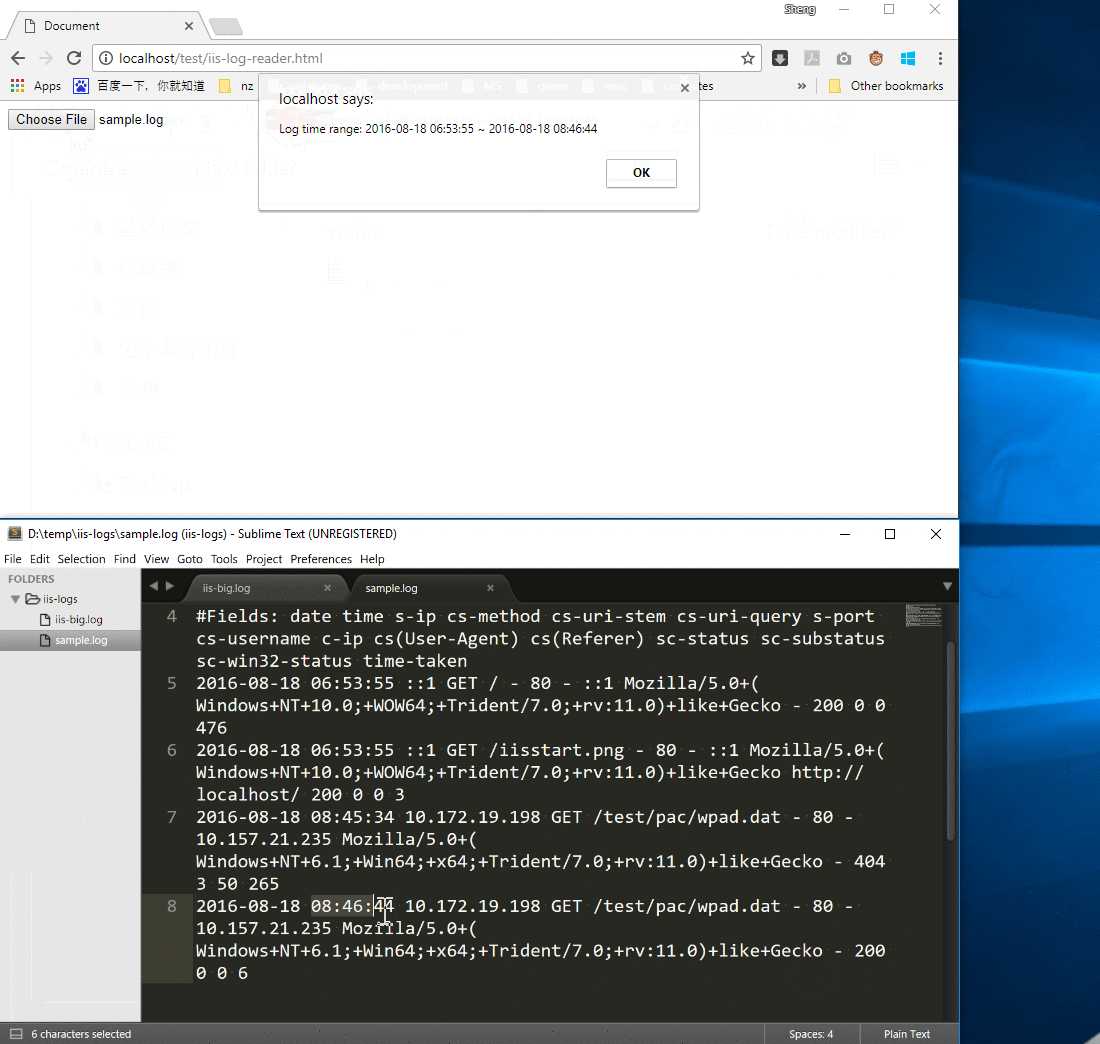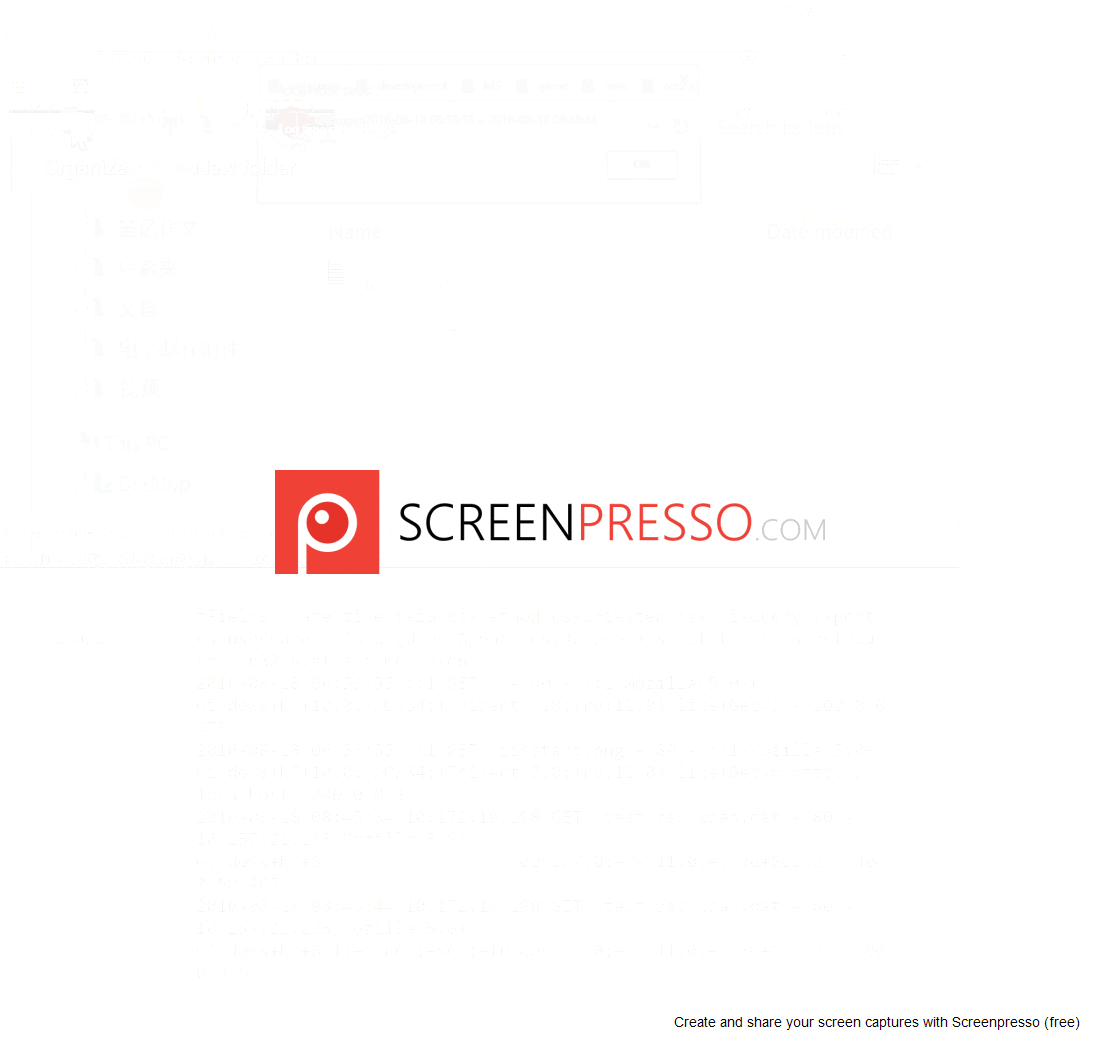
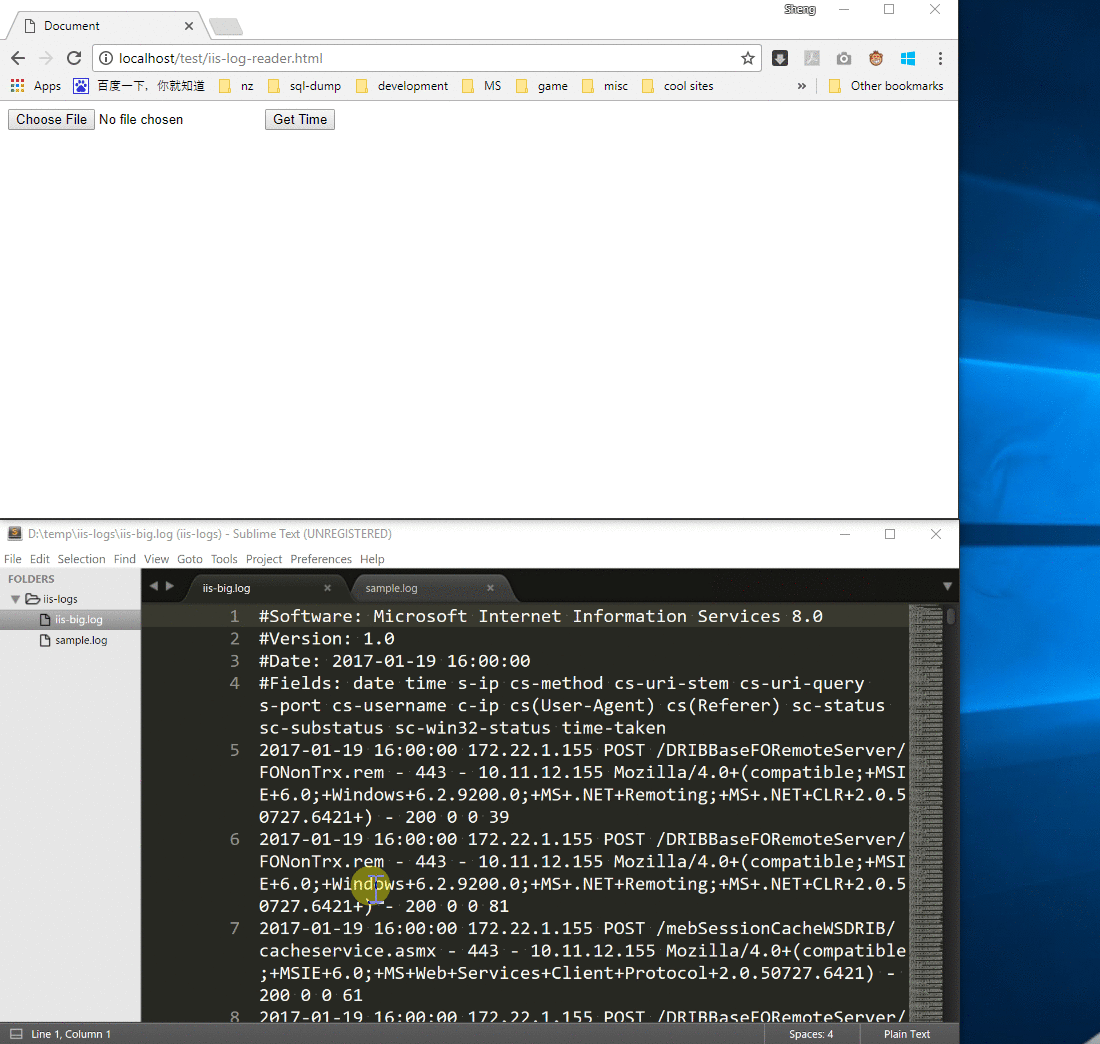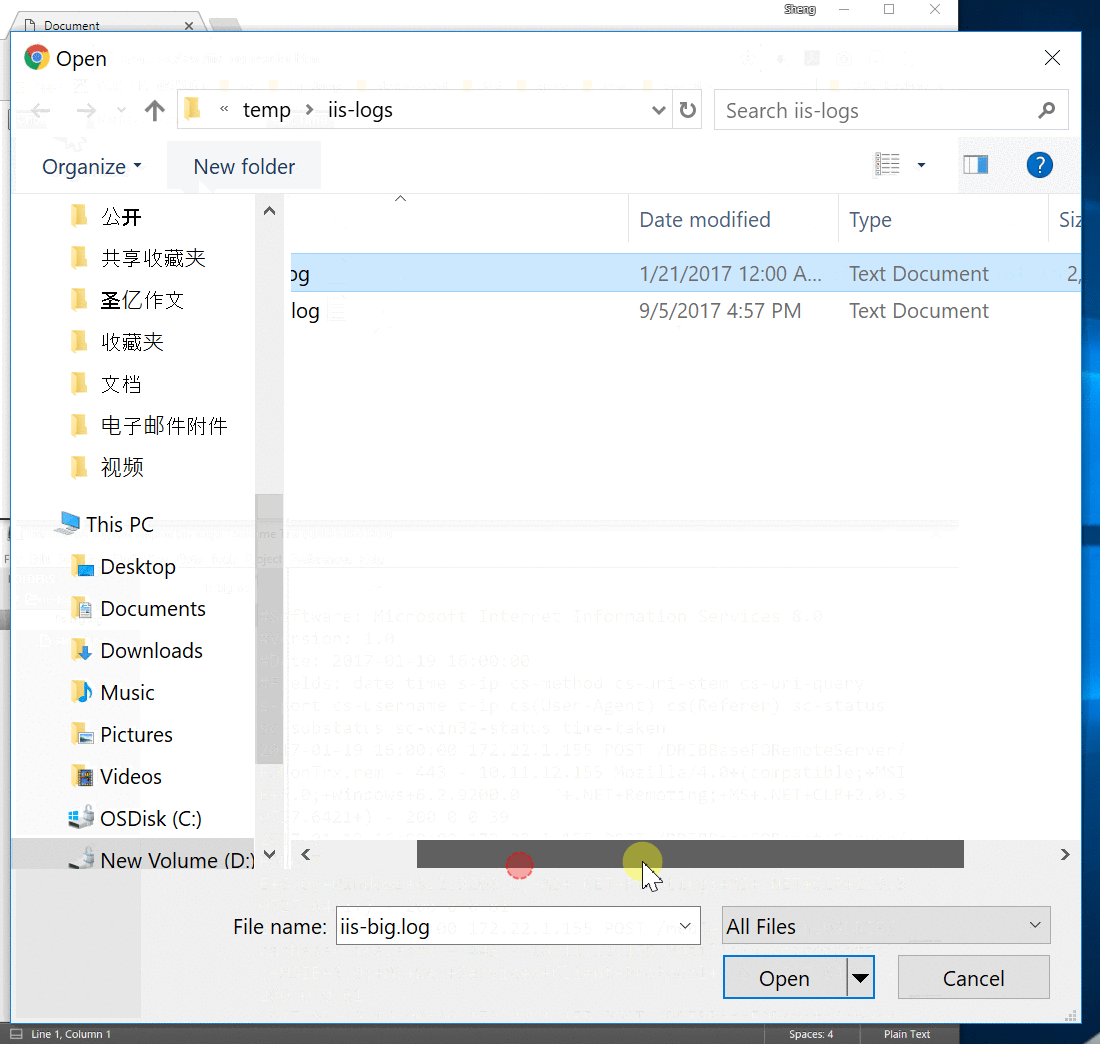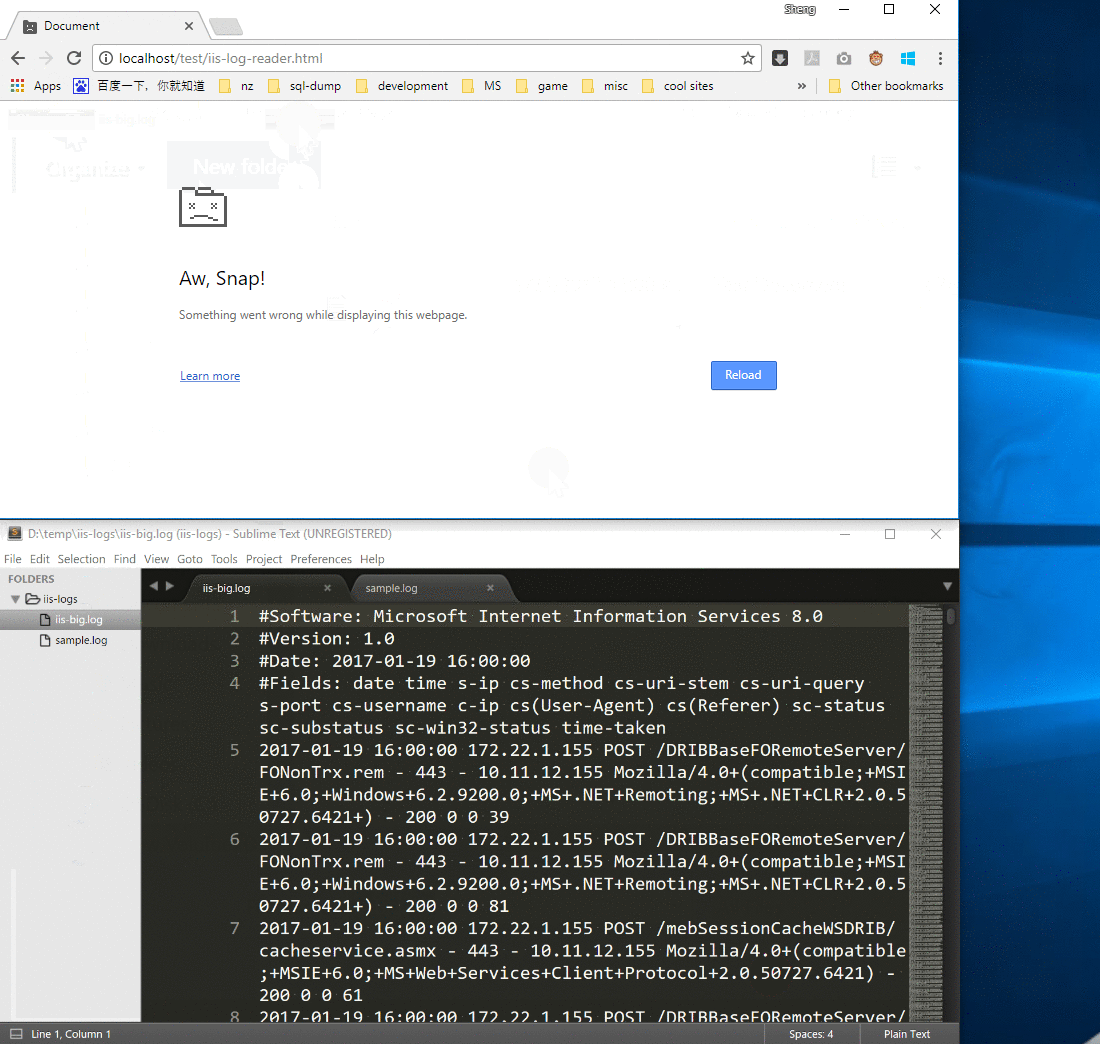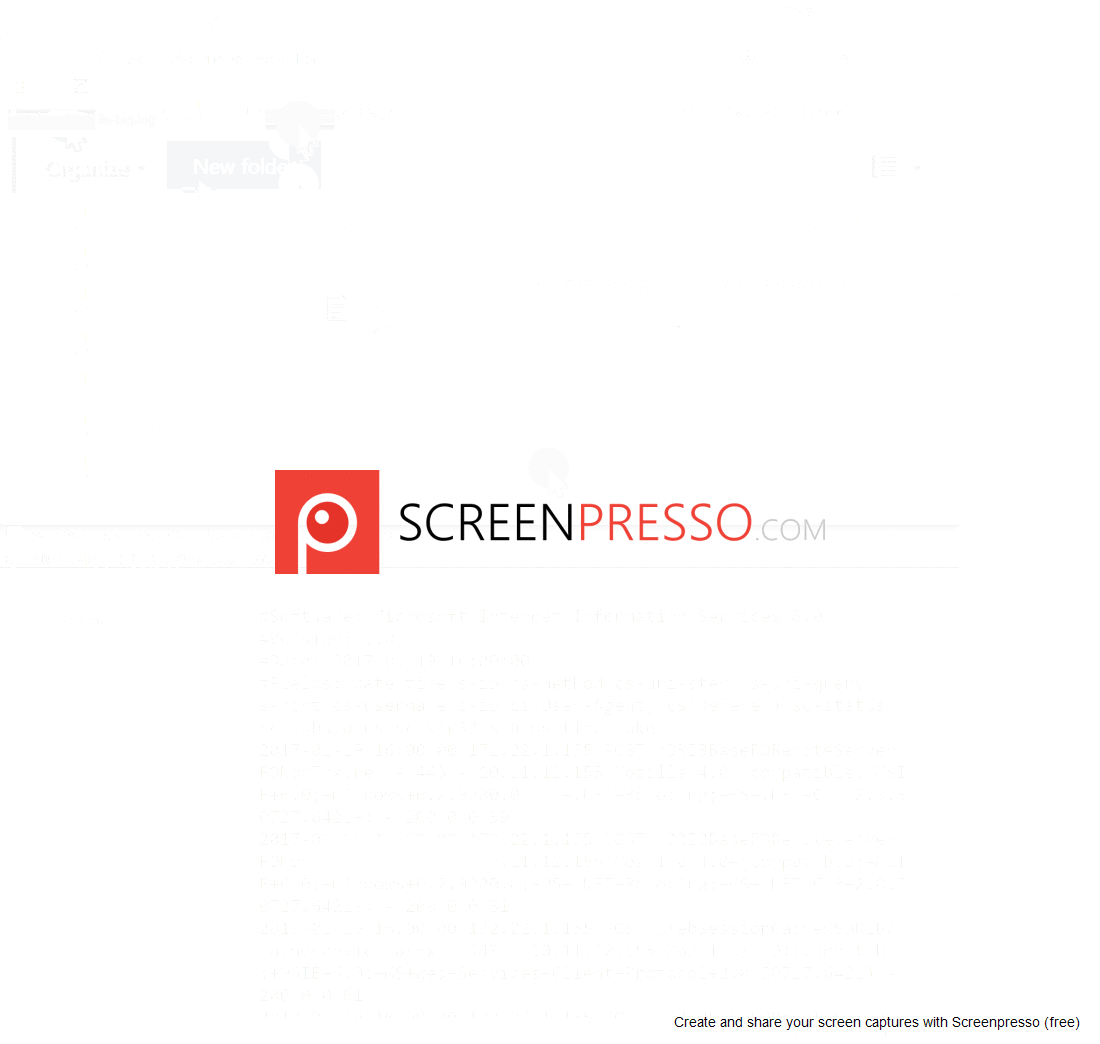
However, the browser crashed if I chose a huge IIS log file (size: 2G) because readAsText() loaded the full file into memory and the process memory exceeds the limitation
Implementation using readAsArrayBuffer()
A File object in JavaScript is inherited from Blob object. We can use Blob.slice() to cut the file into pieces for further processing. The workflow is as below:
- Gets the first 10KB of the file and decode it to text
- Iterates each line from the beginning of the text and checks whether the string of first 19 characters matches the date and time format. If it does, then the string is the start time
- Gets the last 10KB of the file and decode it to text
- In the same way, get the end time by iterating each line from the end
Here is the code:
<input type="file" id="file" />
<button id="get-time">Get Time</button>
<script>
document.getElementById('get-time').onclick = function () {
let file = document.getElementById('file').files[0];
let fr = new FileReader();
let CHUNK_SIZE = 10 * 1024;
let startTime, endTime;
let reverse = false;
fr.onload = function () {
let buffer = new Uint8Array(fr.result);
let timeReg = /\d{4}\-\d{2}\-\d{2} \d{2}:\d{2}:\d{2}/;
for (
let i = reverse ? buffer.length - 1 : 0;
reverse ? i > -1 : i < buffer.length;
reverse ? i-- : i++
) {
if (buffer[i] === 10) {
let snippet = new TextDecoder('utf-8').decode(
buffer.slice(i + 1, i + 20)
);
if (timeReg.exec(snippet)) {
if (!reverse) {
startTime = snippet;
reverse = true;
seek();
} else {
endTime = snippet;
alert(`Log time range: ${startTime} ~ ${endTime}`);
}
break;
}
}
}
};
seek();
function seek() {
let start = reverse ? file.size - CHUNK_SIZE : 0;
let end = reverse ? file.size : CHUNK_SIZE;
let slice = file.slice(start, end);
fr.readAsArrayBuffer(slice);
}
};
</script>
Now we can get the expected result very quickly for a 2GB IIS log after using readAsArrayBuffer.